Intro
网络层向上提供主机到主机的服务,不保证可靠,主要功能是路由和转发,基于IP协议
通常路由器有多个网卡,IP数据包在传送途中会经过多个路由器、途径多个网卡
- 控制平面:路由,数据包应当怎么走
- 数据平面:转发,数据包从哪个网卡出去
SDN
传统的路由算法是在每个路由器上分开跑的,它们之间通过通信来进行数据交换,去中心化地、分布式地运行路由算法。一个比较新的做法是抽出来一个权威的路由计算中心,由它来运行路由算法,路由表则通过分发的方式下载到每个路由器里。SDN(Software Defined Network)说的就是这样的网络。
SDN的好处有这么几个:
- 性能。集中的路由计算可以更快、更优
- 自定义。传统的路由算法可能是写死的固件(要等厂商升级),而SDN可以通过分发不同的路由表来实现不同的功能。例如可以分发拦截名单变成防火墙、分发转发规则变成NAT服务器等等
Router
Components
路由器一般有这么几个组成部分:
- 输入/输出网卡,实现了完整的链路层和物理层功能,有队列用于缓冲,
- switch fabric,我也不知道怎么翻译,大概就是连接输入和输出的部位
- 路由处理器,执行一些网络层协议的算法(例如格式的转换和分片)和路由算法
路由器的转发部件基本上都是硬件实现的,这是为了效率考虑。而路由算法则通常是软件实现的。
Forwarding Table
路由器的转发是以子网为单位的。一个传输中的IP数据包通常包含目标IP地址,而一个连续的IP地址区间被称为一个子网。转发表中通常只记录以子网为最小单位的转发信息(例如位于区间[xxx,yyy]的IP地址将被转发到端口z),否则需要针对每个IP地址维护转发信息,这里有至少 \(2^{32}\) 条。
当然一般用 (IPAddr, prefix)
这样的二元组来表示一个区间。若 addr 的前
prefix 位与 IPAddr 相同则认为
addr
位于这个区间。转发的时候需要找到能匹配到最长前缀的那个转发表项。
Switch Fabric
科普了几种交换的技术:
via memory,相当于用通用计算机来做这件事情。由于需要先写入再读取内存,因此吞吐量只能达到内存吞吐量的一半(B/2),并且任意时刻只能转发一个数据包,没法并行
via bus,相当于用总线把所有输入和输出端口都接起来。由于所有发送方都是广播,因此任意时刻只能转发一个数据包,没法并行。但是总线不需要分开读取和写入,因此吞吐量可以达到完整的总线速率(B)
via interconnection network,其中一种实现长这样。如果所有的数据包互不干扰,那么就可以实现完全的并行转发(NB)。类似的还可以把数据包分片,然后通过这种 fabric 转发,以实现更小粒度的并发(像不像内存分页)
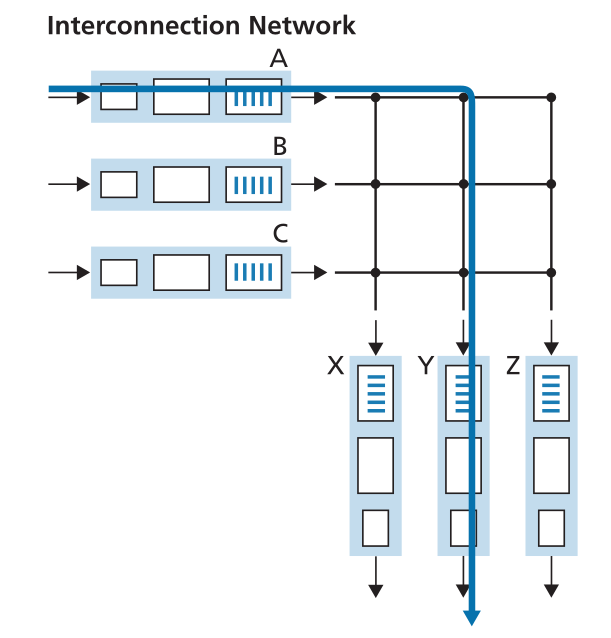
Queue
为什么需要缓冲队列:
- 输入和输出网卡的速率可能不匹配,需要缓冲
- fabric可能会阻塞转发,需要缓冲。某个数据包被队列中排在它前面的包阻塞,这样的情况叫HOL blocking(Head of Line 阻塞)
当队列大到一定程度时路由器会被迫丢掉若干数据包,这里就有一个 victim choice 的问题。
队列的长度限制也是一个需要调好的参数,太短则容易频繁丢包,太长则容易造成延迟(某些实时的数据包会因此而失去意义)。传统的推荐大小是
RTT*C,最近的研究则认为应该是
RTT*C/SQRT(N),其中 C
是链路带宽,N 是 TCP 连接数,RTT 一般为
250ms
Packet Scheduling
谈来谈去就是那么几个
- FIFO
- 分优先级
- RR
- WFQ/MLFQ
IPv4
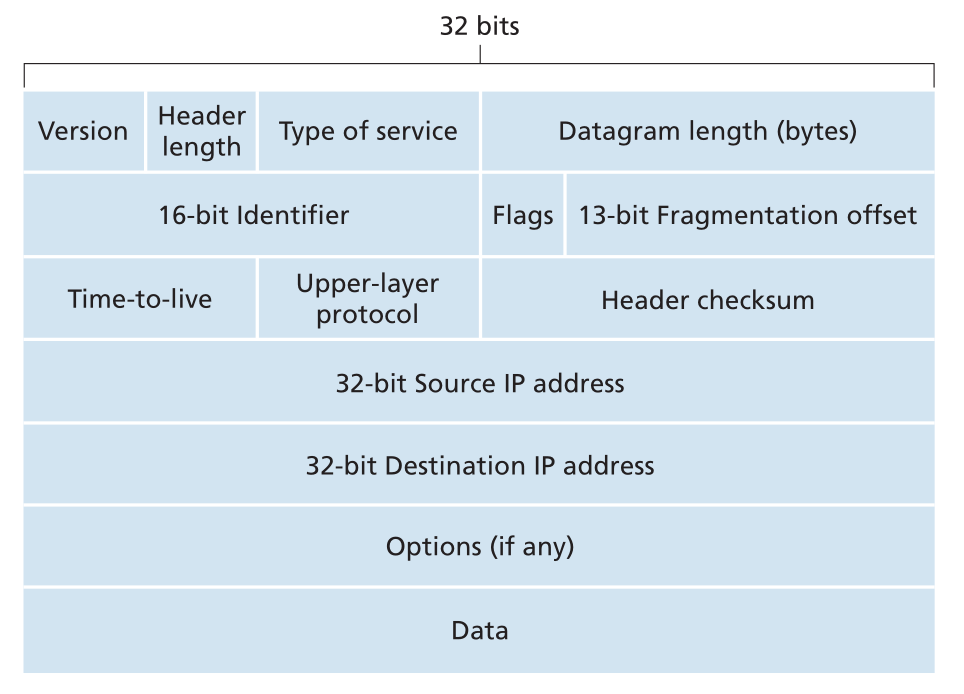
有几个比较重要的 field
- header 长度,因为有可选项
- 总长度
- identifier, flags, fragmentation offset。这三个主要是为了实现 IPv4 包的分片,即 IPv4 允许包在传输途中被切分(只要最终是完整的就行)。
- TTL
- header checksum
- 源IP和目标IP
Addressing
每个主机和路由器的端口都需要有一个IP,网络层的数据包从一个IP地址发往另一个IP地址
理论上每个主机和路由器的端口都有全局唯一的IP地址(用于辨认身份),在不考虑 NAT 的情况下也确实如此。
255.255.255.255
这个全1的地址是广播地址,向这个地址发包将会向子网内所有拥有IP地址的设备发包
子网
CIDR=Classless Interdomain Routing
子网指的是一段前缀相同、连续的IP地址的集合。通常用 \(\text{(prefix,len)}\)
这样的二元组来描述一个子网。例如 223.1.1.0/24
指的就是前24位与 223.1.1.0
完全相同的所有IP地址的集合,它们组成一个子网。
CA=Classful Addressing
说的是只能按照 /8 /16 /24
进行子网划分,分别叫A类、B类、C类网络
统计子网可以删去所有的节点(主机/路由器),剩下联通块的数量就是子网的数量。即两个节点之间如果不需要额外的主机和路由器即可通信,那么它们同属一个子网。
DHCP
手动分配IP是很痛苦的事情,DHCP(Dynamic Host Configuration Protocol)做的就是让主机来自适应地获取它被分配到的IP地址。
DHCP一般会有一个子网内的服务器,协议步骤如下:
造一个UDP包,端口67,从
0.0.0.0发往255.255.255.255UDP和67都是任意的,全0是因为当前主机还没有分配任何IP地址,广播是因为当前主机不知道DHCP服务器的IP地址
服务器收到这个广播,然后也发一个广播。从服务器的IP地址发往
255.255.255.255,提供- transaction ID,用于标记这是哪一次DHCP交互
- IP地址
- 子网
- 有效时间
这时广播仍然是因为主机还没有IP地址,有效时间使得DHCP服务器可以定时更换主机的IP地址,或者收回地址资源(考虑主机频繁出入的无限局域网)。
主机收到这个广播,向目标IP地址发一个确认消息
服务器收到确认消息,向分配的IP地址发一个确认消息
NAT
IPv4地址显然是不够用的,因此引入NAT(Network Address Translator)来缓解全局IP地址不够用的问题。
NAT本质上是利用一个拥有公网IP地址的主机作为代理,实现了 \(\text{\texttt{(private\_ip,private\_port)}}\mapsto\texttt{(NAT\_ip,NAT\_port)}\) 的翻译。即私有网络中不同IP的主机,最终都被映射到了同一个NAT的公网IP的不同端口上。
引入NAT也会引入一些问题,例如在P2P应用中经典端口被占用,这使得私有网络中的主机没法做server。
IPv6
主要有几个变化
- 地址长度变成了128位
- header 定长
- 没有 checksum
- 不允许划分IP数据包
Tunneling
即如何让新协议跑在旧屎山硬件上。
非常简单,把IPv6的整个包作为IPv4的数据中途传输即可。这个操作就叫隧穿。
Routing
主要科普几个路由算法,要会做题。主要分为:
- 中心化/分布式
- 动态/静态
- 负载敏感/不敏感,说的是会不会考虑瞬时的拥塞状况
Link-State
- 所有节点通过广播获得全局信息
- 每个节点单独地以自己为起点跑Dijkstra算出到其余点的最短路径
- 更新路由表
oscillations 指的是一类考虑瞬时负载时出现的问题,我们的路由算法可能会在两条路径之间来回震荡
- 选择路径1,此时路径1拥塞,路径2畅通
- 第二轮选择路径2,此时路径2拥塞,路径1畅通
- 反复
解决的方法课本给了两种:
- 避免参考瞬时的链路评估
- 避免所有的路由器同时运行LS路由算法
做题的时候一般默认所有路由器得到相同的全局观,且同时完成算法。
Distance-Vector
- 每个节点只有局部的信息,向外广播自己的视角,通过接收广播来更新自己的视角
- 每个节点根据当前视角、所有邻居的局部信息更新自己的视角
- 更新路由表
本质上是在跑一个并行的bellman-ford
做题的时候一般默认每一轮都是同时进行的,并且每一轮只能看到上一轮的邻居视角。
可能出现 count-to-infinity 的问题:
- 中途链路代价的变化可能导致出现环,从而一个包没法正确送到目的地
- 在逐渐适应链路变化的过程中,环将一直存在,并且这个过程可能比较长
解决这个问题的办法之一是给边的正反方向赋予不同的代价,以引导算法不走环。
Poisoned Reverse 指的是这样的处理:
如果 x 途径 y 到达 z,那么 x 就会向 y 汇报自己到 z 的距离是 \(\infty\)
可以发现这样实际上避免了边 \(xy\) 被重复连续走两次。但这样避免不了更大的圈的问题。
对比
- LS需要交换全局信息,而DV不需要
- LS的复杂度就是Dijkstra的复杂度,而DV的收敛取决于链路状况
- LS的每个节点独立计算路由表,相对隔离;而DV在计算途中会传播计算结果
OSPF
这是一种 intra-AS(Autonomous System) 路由算法,即在一组路由器内部进行路由的算法。
OSPF 属于 Link-State 协议,加入了一些特色
- MD5校验,加强安全性
- 允许同时使用多条代价相同的路径
- 支持AS内部继续分组(sub-AS)
BGP
BGP 是一种 inter-AS 路由协议,即在一堆的路由器集合之间进行路由的算法。
所有的路由器被划分成两种:internal 和 gateway,分别运行 intra-AS 和 inter-AS 的协议。
运行 BGP 协议路由器的路由表以子网为单位,两个路由器通过 BGP connection 交换信息
- 处于同一 AS 的路由器间的连接叫 iBGP(internal)
- 处于不同 AS 的路由器间的连接叫 eBGP(external)
分发信息
本质上是一个三元组
(AS-PATH, NEXT_HOP, TARGET_SUBNET_MASK),分别表示从当前 AS
出发到达新主机的一条路径,和这条路径上第一个离开当前AS的路由器的IP地址,以及目标AS的子网掩码。
某个主机会通过 iBGP 向 AS 内的路由器传达存在性,然后通过一个 external 路由器向外,借助 eBGP 给另一个 AS 传达新主机的存在性
在传达的途中,消息会被逐渐附加上消息途径的路径,这样接收方就能反推出到达新主机的路径了。同时消息会逐步更新
NEXT_HOP,这是因为这个信息只对当前 AS
有用,因此可以覆盖
选择路径
不妨假设有许多从当前 AS 到达目标子网的 BGP 路径信息,我们需要选出一条来
Hot potato routing
即挑出一条路径使得当前路由器到 NEXT_HOP 的代价最小(通过
intra-AS 协议获得的信息)。这么做的 idea
在于尽可能快地让这个数据包离开当前 AS。
Route-selection algorithm
按照顺序执行下述策略
- 可以人为设置一个偏好值,例如更便宜的链路
- 挑
AS-PATH最短的 - hot potato
- 通过 BGP-identifier 排序,虽然我感觉这里顺序是无所谓的
IP-cast
- multicast,某个IP对应了一组设备
- unicast,某个IP对应一台设备
- broadcast,某个IP对应广播范围内所有设备
- anycast,某个IP对应一组设备中的任意一个设备
前面提到的 DNS 可以做到域名的各种cast,而这里则是在IP层面实现的。
通过 BGP 协议,我们可以布置许多服务器,然后给它们分配相同的 IP 地址,这样在进行 BGP 广播的时候,接收方 AS 将会认为存在多条路径通往同一个主机(而真实的情况是存在多条路径通往多个不同的主机,这些主机恰好提供相同的服务),然后根据路由选择算法挑一条路径出来(也就是挑一个主机出来)。
稍微想想就会发现这样可能出现数据包交错发的情况,因为 BGP 的路由选择算法本质上是启发式的。因此面向连接的协议就比较难办,例如 TCP。而 DNS 这种基于 UDP 的服务就很方便,短平快而且实现了 IP 层面的负载均衡。